在進入實作部分之前,我們將最後探討一些大型語言模型特有的現象,以及在實際應用時經常使用的提示策略。
雖然大型模型因其強大的能力而受到廣泛的關注,但其中一個較少為人知的特性是“湧現能力”(Emergent Abilities),我們也可以稱它為頓悟現象。
在2022年,DeepMind發表了一篇名為 "Emergent Abilities of Large Language Models" 的論文,其中包括一張引人注目的圖表: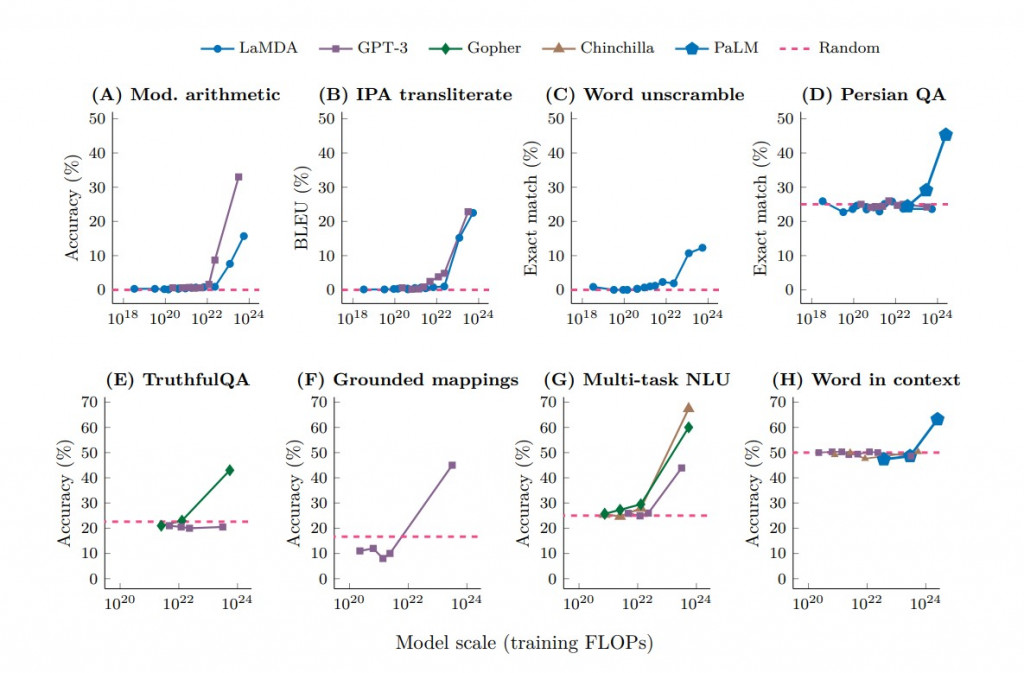
(圖表引用自 Emergent Abilities of Large Language Models)
這個圖表揭示了一件事情,當模型的規模和複雜度達到一定程度後,原先表現一般的模型會突然展示出意想不到的能力。例如上圖的表A中顯示,對於邏輯運算問題,GPT-3和LaMDA在模型參數少於約100億(10B)時,其準確度接近於零,與隨機猜測(圖中紅色虛線基準線的意義)無異。
然而,當模型規模擴大到一定程度(例如,GPT-3達到約130億,LaMDA達到約680億)時,準確率會突然大幅提升。這一趨勢在其他七個不同的任務中也有類似的表現。
這種現象也就是知名的大型語言模型的頓悟現象。它就像我們人們的學習一樣,總是會有前期一段全然不知、懵懂、一知半解的時期,而當你知識累積到某個程度後,會在某個時間點突然茅塞頓開。
下一個值得討論的主題來自於 "Language Models (Mostly) Know What They Know" 這篇論文。這篇論文提到,大型語言模型內部的知識往往比其原始輸出更為豐富。通過適當的引導,這些模型可以達到出乎意料的效果。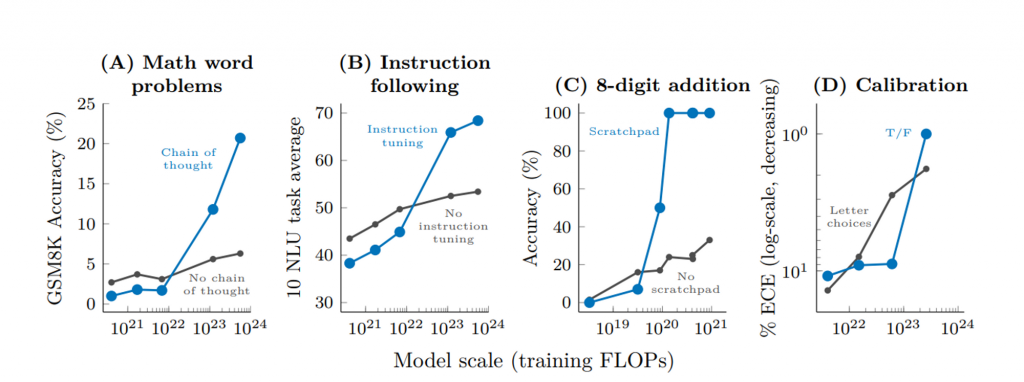
(圖表引用自 Emergent Abilities of Large Language Models)
這張圖表展示了大型語言模型規模與四種不同任務(即ABCD)的回答準確度之間的關係。在橫軸上,您會看到"Model Scale",代表的是訓練模型的計算量,你也可以將它簡單當作模型的規模,而縱軸則表示回答的準確度。
圖中主要有兩條曲線:黑色曲線代表未經調教的原始模型的表現,而藍色曲線則為經過專門調教後的模型的表現。令人驚訝的是,在模型規模低於某個臨界值時,調教後的模型的表現不僅未能優於原始模型,反而略顯遜色。然而,當模型規模超過那個臨界點後,經過調教的模型的準確度會迅速攀升,遠超未經調教的原始模型。
具體來說,在圖A中,經過「Chain of Thought」引導調教的模型(藍色曲線)在準確度上達到了20%,這一數字遠高於同樣任務下未經調教的原始模型(黑色曲線)的6%。這種臨界點效應強調了細心調校模型在某些情況下的重要性,特別是當模型規模達到或超過這一臨界值時。
接下來,我們將與大家分享一些在實際應用場景中經常被運用的提示技巧。
在現代的大型語言模型(例如 GPT)中,由於已經進行了指令微調(Instruction Tuning),我們可以直接用日常語言來提問或給予指令,而不需要對模型進行任何額外的訓練。這就是所謂的"零樣本提示"。
舉例來說:
提示詞:
將下方的文字分類為「正向」、「負面」或「無情緒」
文字: 今天天氣真好
分類:
模型的回覆:
正向
這樣的方式非常適合一般人使用,因為它簡單直接。你只需要用平常和人溝通的方式來對話,模型就能理解你的需求並給出相對應的回應。
大型語言模型如 GPT 在單一或簡單指令下(即零樣本提示)已經表現得相當出色。然而,對於更複雜或特定的問題,模型可能仍然無法準確地回答。這時,我們可以使用「少量樣本提示」來增強模型的表現。
這種方法的核心思想是提供幾個與目標任務相關的範例,以便模型能更好地了解你的需求。這種做法對於解決更複雜或專門的問題特別有用。
舉例來說:
提示詞:
蘋果是紅色的,所以我們使用下面的句子來形容蘋果。
例句: 蘋果看起來紅通通的,真好吃。
那麼,棗子是綠色的,要如何形容棗子呢?
模型的回覆:
例句:棗子呈現綠油油的外皮,讓人垂涎欲滴。
使用如上的小量樣本提示,模型就能夠更準確地捕捉到你的需求,並提供更貼近目標的回應。這種提示技巧,讓我們即使是在面對複雜任務時,只要我們稍加說明就能立即獲得更精確的結果。
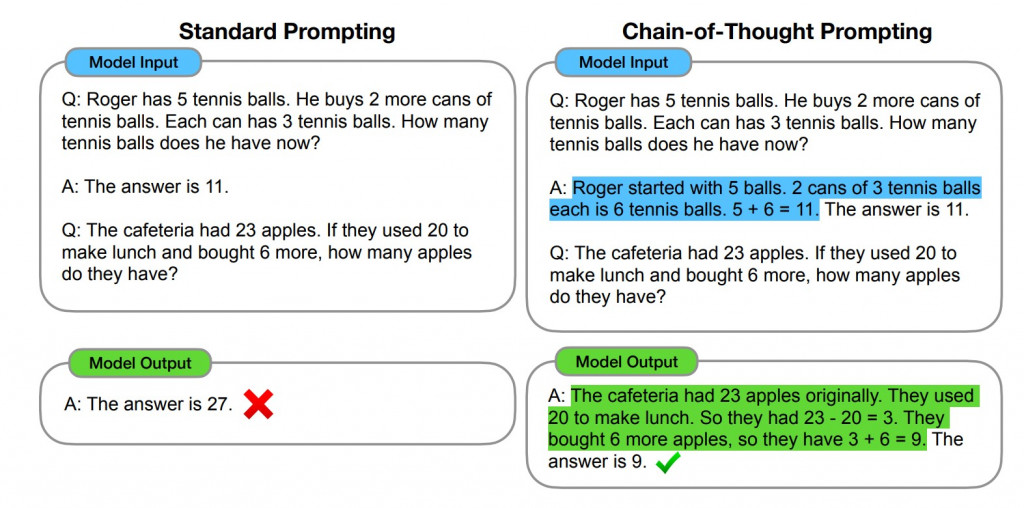
這個技巧其實就是教大型語言模型如何"思考"。有時候,如果你直接問模型一個複雜的問題,它可能會給你一個不太準確的答案。為什麼呢?因為它雖然看似有點邏輯能力高,但是卻又可能沒有足夠的思考能力來完全推論你的問題。
舉例來說,如果你以如下方的方式直接詢問語言模型:
Q: 羅傑有5個網球。他再購入了2罐網球,每罐裡有3個網球。現在他共有多少個網球?
A: 答案是11。
Q: 自助餐廳裏有23個蘋果。 如果他們用 20 個做午餐,又買了 6 個,他們有多少個蘋果?
語言模型則由於沒有足夠的思考時間,所以會給你一個錯誤的答案:
A: 答案是27。
這時,你可以使用"思維鏈提示"來改善這種情況。這基本上就是將問題拆解,並讓模型跟著你的思維過程走。這樣模型就更有可能給出正確的答案。
例如下方是我們改進後的提示內容:
Q: 羅傑有5個網球。他又買了2罐網球,每罐裡有3個網球。現在他共有多少個網球?
A: 羅傑起初有5個網球。他購入的2罐網球,每罐有3個,總共是6個。5加上6等於11,所以答案是11。
這樣,模型就能更精確地回答問題了,以下是改進後的模型回覆。
A: 食堂原有23顆蘋果。使用了20顆做午餐,剩下的是3顆。再加上新買的6顆,總共就有9顆蘋果。答案是9。
以上這些提示技巧都是為了讓大型語言模型更能了解我們的問題,從而提供更精確的答案。我們將在接下來的實作部分進一步探討這些技巧,敬請各位期待!
這一段是否有誤?
舉例來說,如果你問:“羅傑有5個網球,又買了2罐每罐3個的網球,現在他有幾個網球?”模型可能會錯誤地回答"11"
正確答案不是 11 個嗎?就像是你文章下一段給的範例:
Q: 羅傑有5個網球。他又買了2罐網球,每罐裡有3個網球。現在他共有多少個網球?
A: 羅傑起初有5個網球。他購入的2罐網球,每罐有3個,總共是6個。5加上6等於11,所以答案是11。
您好,您反應的段落的確有筆誤,已經直接在原文中修正了,希望這樣的表達足夠清晰。
很謝謝你的反應。


 iThome鐵人賽
iThome鐵人賽